
Welcome to the ODI
Knowledge for everyone
The ODI helps to unlock the value of open data.
If you want to use our logo, different sizes and types are here: http://theodi.org/brand


Ah, the mid-nineties; good times. Personally, I spent them drinking in student bars, listening to BritPop, and exploring the early web as it grew from just a few sites into something that would change the world.
There was a lot out there, but it was hard to find, so a load of companies were stepping in to try to catalogue it. Yahoo! and Lycos launched in 1995 with their portals, so we had a whole load of stuff to explore instead of going to lectures. Fantastic. But then, the web grew, and things changed. HotBot and Altavista came along, and changed the game from cataloguing to search. Not long after that, along came Google, and the stage was set. Portals were dead, because the web was bigger than anyone could keep up with.
Now, with the web of data, we’re on a similar journey 20 years later. We’ve got our sites and we’ve built our portals, but we don’t yet have the rich, organic web that we’re used to with documents. As the amount of data on the web expands, as data publishing gets more and more mainstream, we’re going to need to do better. We’re going to need search.
At the ODI, we think a lot about the future of the web of data, and we also get time to experiment, so a few weeks ago I spent some of my spare time playing around to see what organic data search might be like. I use DuckDuckGo as my primary search engine these days, and it has some great features, like instant answers that pop up to show image or video results, amongst many other things. Wouldn’t it be great to see that for data? Imagine searching for some information, and at the top, a load of open datasets pop up with exactly the answer you want.
Well, as some of DuckDuckGo is open source, we can have a go ourselves. You can create your own plugins using their really well put together development platform. Creating the plugins themselves is also pretty simple, and there’s lots of documentation.
Question is, how do we find the datasets? Real search engines crawl the web, and find everything, but I’m going to cheat. We have a database of almost 10,000 open datasets listed on the Open Data Certificates site, and we can use that to drive our search results. Note: this would not be a good idea for a real search engine; it’s not built to drive the kind of queries we’d need, and it doesn’t crawl the web at large (yet). However, it will do for this experiment.
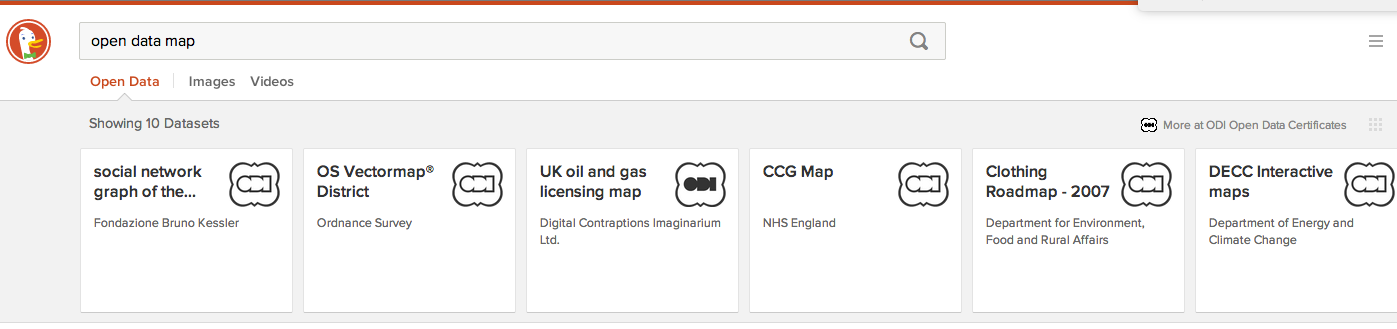
With a bit of hacking around, we can create a DuckDuckGo plugin which, whenever you enter the search term “open data X”, will go to the Open Data Certificates API, search for X, and present the results back to you at the top of your normal search results. It shows the name, publisher, and certification level. If you click, it will take you straight to the page that describes the data (normally on data.gov.uk). Brilliant!
You can see the code that does this in our fork of DuckDuckGo’s zeroclickinfo-spice repository. Unfortunately, it’s not in the real search engine, and I won’t be submitting it, because it needs a proper search index behind it. However, we’ll be looking for ways to spend some time on a project to build that search index, and work on other things like ranking, so stay tuned.
This isn’t by any means a complete attempt at data search, but it’s an interesting experiment that maybe pushes us a little bit towards the future of the true web of data.