
Welcome to the ODI
Knowledge for everyone
The ODI helps to unlock the value of open data.
If you want to use our logo, different sizes and types are here: http://theodi.org/brand


The ODI tech team has recently been building a tool to validate CSV files. While CSV is a very simple format, it is surprisingly easy to create files that are hard for others to use.
The tool we’ve created is called CSVLint and this blog post provides some background on why we’ve built the tool, its key features, and why we think it can help improve the quality of a large amount of open data.
Jeni Tennison recently described 2014 as the Year of CSV. A lot, perhaps even the majority, of Open Data is published in the tabular format CSV. CSV has many short-comings, but is very widely supported and can be easy to use.
Unfortunately though, lots of CSV data is published in broken and inconsistent ways. There are numerous reasons why this happens, but two of the key issues are that:
This case study on the status of CSVs on data.gov.uk highlights the size of this issue: only a third of the data was machine-readable.
These types of issues can be addressed by better tooling. Validation tools can help guide data publishers towards best practices providing them with a means to check data before it is published to ensure it is usable. Validation tools can also help re-users check data before it is consumed and provide useful feedback to publishers on issues.
This is the motivation behind CSVLint.
To ensure that we were building a tool that would meet the needs of a variety of users, we gathered requirements from several sources:
We used this input to refine an initial set of features which formed the backlog for the project. The key things that we needed to deliver were:
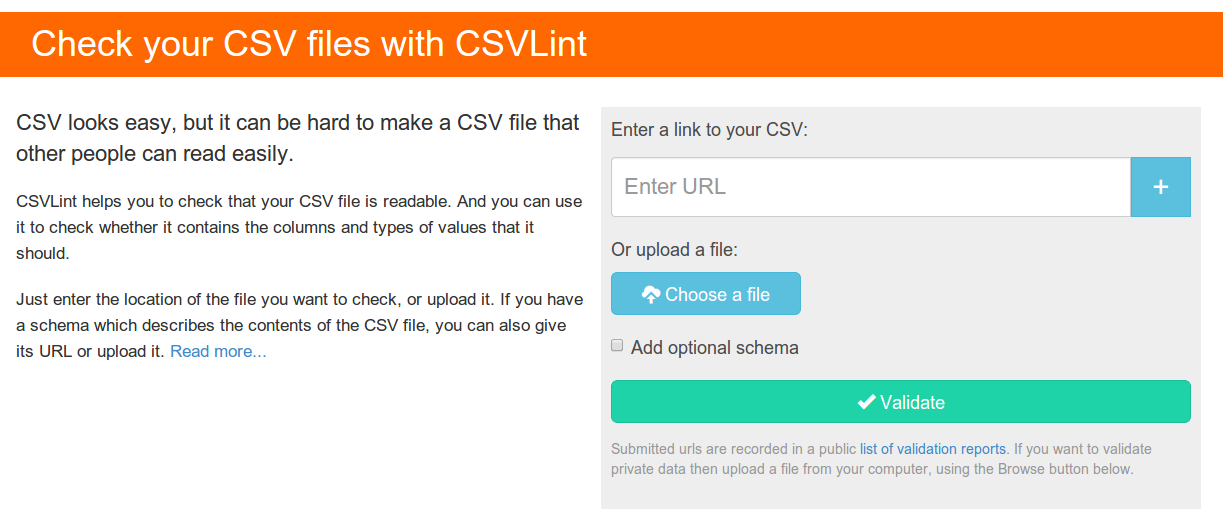
The end result of our efforts is CSVLint an open service that supports the validation of CSV files published in a variety of ways.
The service is made up of two components. The web application provides all of the user facing functionality, including the reporting, etc. It is backed by an underlying software library, csvlint.rb, that does all of the heavy lifting around data validation.
Both the web application and the library are open source. This means that everything we’ve built is available for others to customise, improve, or re-deploy.
The service builds on some existing work by the Open Knowledge Foundation, including the CSV dialect, JSON Table Schema and Data Package formats.
CSVLint supports validating CSV data that has been published in a variety of different ways:
Data uploaded to the tool is deemed to be “pre-publication” so the validation reports are not logged. This allows publishers to validate and improve their data files before making them public.
All other data is deemed to be public and validation reports are added to the list of recent validations. This provides a feedback loop to help highlight common errors.
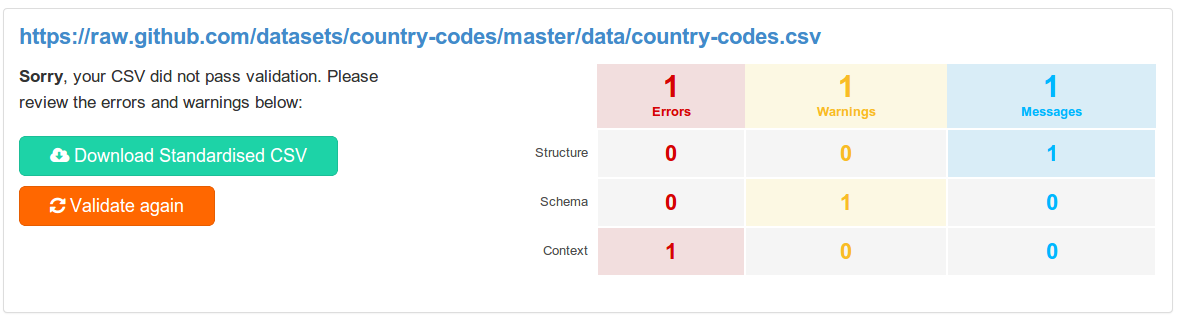
The validation reports (example) have been designed to give “at a glance” feedback on the results, as well as a detailed breakdown of each issue.
All feedback is classified along two different dimensions:
Content-Type used to serve the fileThe summary table for each validation result is supplemented with detailed feedback on every reported issue with suggested improvements.
The report also includes badges that allow a summary result and a link to a full report to be embedded in other web applications.
A JSON view of a validation result provides other integration options.
In addition to checking structural problems with CSV files, the CSVLint service can also validate a file against a schema.
We proposed some suggested improvements to the JSON Table Schema format that would allow constraints to be expressed for individual fields in a table, e.g. minimum length, patterns, etc. These have now been incorporated into the latest version of the specification.
CSVLint currently supports schemas based on the latest version of JSON Table Schema. There is some background in the documentation (see “How To Write a Schema”) and it is possible to see a list of recently used schemas to view further examples.
Using a schema it is possible to perform additional checks, including:
This provides a lot of flexibility for checking the data contained in a CSV file. When validating a file a user may specify a schema file to be used when validating the data, either uploading it with the data or pointing to an existing schema that has been published to the web. For Data Packages any built-in schema is automatically applied. Schemas can be uploaded along with a data file or published openly on the web.
CSVLint automatically generates some summary documentation for schemas loaded from the web, e.g. this schema for the Land Registry Price Paid data.
While CSLint is still an alpha release there are already a rich set of features available to support guiding and improving data publication. We think that the service can potentially play a number of roles:
But to prove this we need people to start using the tool. User feedback will provide us with useful guidance on how the service might evolve. So we’re really keen to get feedback on how well CSVLint supports your particular data publication or re-use use case.
Please try out the service and share your experience by leaving a comment on this blog post. If you encounter a bug, or have an idea for a new feature, then please file an issue.